
Künstliche Intelligenz im Maschinenbau
Die Wettbewerbsfähigkeit von Unternehmen hängt stark von der Fähigkeit ab, die eigenen Unternehmensdaten systematisch zu nutzen und Prozesse mit perfekten Daten automatisiert zu beliefern.

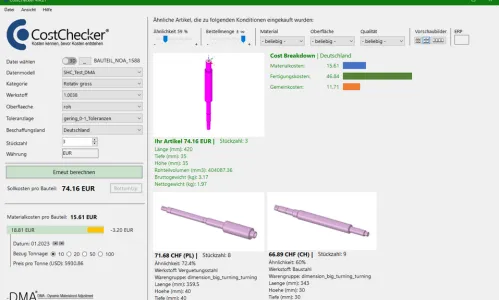

Einsparungen durch vollautomatische Bündelung
Manchmal ist die Anzahl und die Varianz der Bauteile in Unternehmen unvorstellbar hoch. Menschen können ein paar hundert Artikel überblicken ... aber 70'000?

Next Level Transparency im Einkauf
In konjunkturell - und geopolitisch anspruchsvollen Zeiten sind verlässliche Unternehmensdaten das Gebot der Stunde. Wir mussten aber schnell feststellen: Einkäufer haben eine andere Vorstellung von "Transparenz" und "verlässlichen Daten" als wir. Aber der Reihe nach ...


Teileallocation mit Machine Learning
Kürzlich stand bei einem Kunden folgende Fragestellung im Raum: "Welche der bestehenden NC-Maschinen ist für unsere intern und extern gefertigten Artikel die "Richtige", um optimale Fertigungszeiten, minimale Rüstkosten und eine hohe Effizient zu erreichen"?

Auf Besuch bei costdata - Oh wie schön ist Köln
In Köln wird erstmal getrunken. Gefühlt haben costdata Gmbh - vertreten durch Tobias Uding und Frank Weinert - und ich, an unserem Treffen alle Kneipen durchprobiert. Ob "Gaffel", "Pfäffgen" oder "Früh" ...
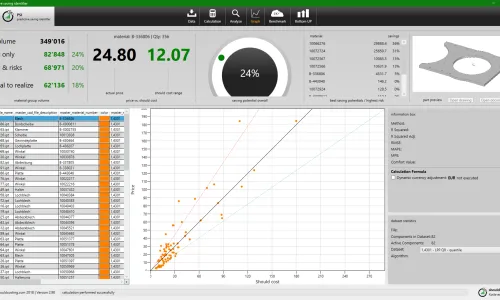
With AI and Data to Procurement Excellence
Generally, suppliers have an edge on information over their customers. They know exactly how high their production costs are.
